
 العربية
العربية Español
Español 中文
中文 Deutsch
Deutsch Français
Français Português
Português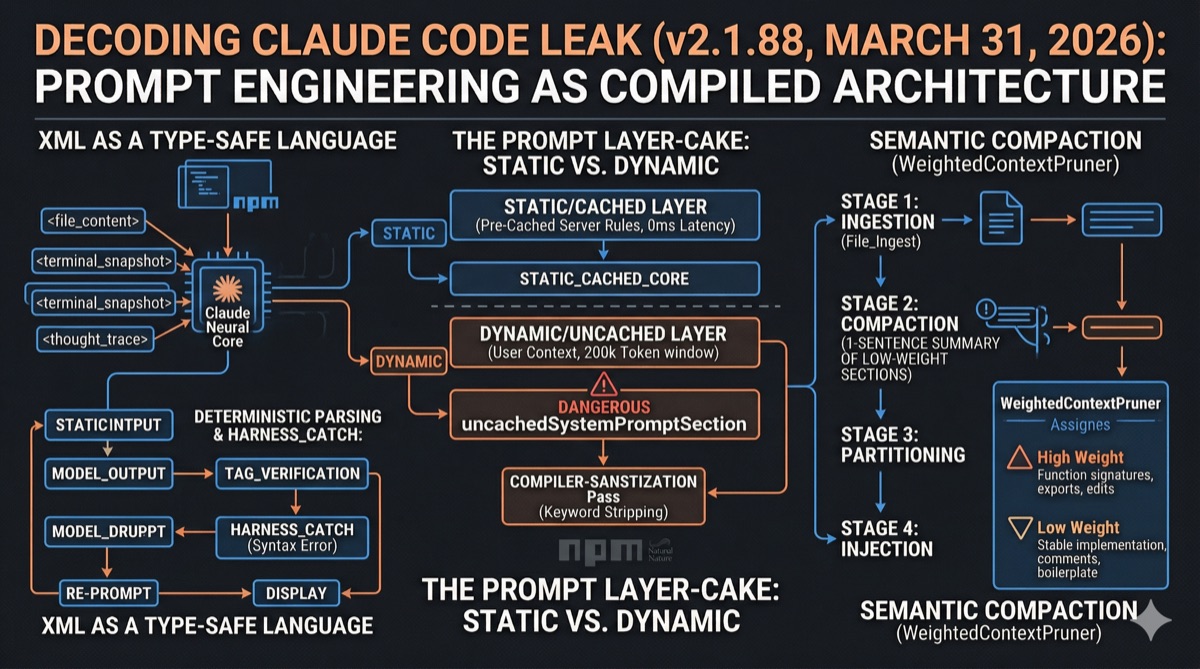
This is Part 4 of a 5-part series: "The Architecture of Agency." Part 1: the harness. Part 2: the model roadmap. Part 3: KAIROS daemon. Now we examine the "dark matter" of the codebase: how Anthropic treats prompts as compiled software, not strings.
Most developers think of prompt engineering as writing clever sentences in a chat box. The leaked src/prompts/ directory and internal utilities reveal something radically different: for Anthropic, prompt engineering is compiled software architecture with versioning, caching layers, security boundaries, and anti-tampering mechanisms.
1. The "Dangerous" Boundary: Static vs. Dynamic Prompt Partitioning
The most revealing naming convention in the entire leak: DANGEROUS_uncachedSystemPromptSection().
1.1 The Architecture
Anthropic strictly partitions the system prompt using a SYSTEM_PROMPT_DYNAMIC_BOUNDARY marker:
| Layer | Contents | Caching | Cost |
| Static | Hard-coded rules (behavioral guidelines, tool definitions, safety constraints). Same for all users. | Pre-cached on server | Paid once, reused indefinitely |
| Dynamic | User’s specific context: CLAUDE.md files, current task, conversation history, tool results | Uncached (DANGEROUS) | Recomputed every turn |
Why "DANGEROUS"? Any code that allows the user to influence system-level instructions is explicitly flagged as dangerous in the source. This isn’t just a naming convention — it’s a cost and security boundary. Every change to an uncached section forces recomputation of tokens that would otherwise be free. Engineers see the annotation and know: "changing this costs money and introduces security risk."
1.2 The Economics of Prompt Caching
This partitioning is driven by hard economics. With Anthropic’s token-based pricing, cache invalidation becomes an accounting problem, not just a computer science one.
The leaked promptCacheBreakDetection.ts tracks 14 distinct cache-break vectors — 14 different ways the prompt cache can be invalidated during a session:
- Model tier changes (switching between Opus/Sonnet/Haiku)
- Tool definition updates
- Permission mode changes
- Feature flag toggles
- System reminder injections
- And 9 others
The code implements "sticky latches": once a cache-breaking action occurs, the system does not attempt to restore the cache. It stays broken for the rest of the session.
The User-Facing Impact: This explains a pattern many power users have noticed: sessions that start fast gradually slow down. Each configuration change accumulates cache breaks. The sticky latch design means you cannot recover by reverting the change — the cache is gone for that session. Starting a new session resets all latches.
2. XML as a "Type-Safe" Language for AI
The leak confirms that Claude is specifically tuned to treat XML tags as strict code boundaries — not just markup, but a type system for reasoning.
2.1 The Tag Architecture
The codebase reveals a library (xml-builder-agent) that wraps every piece of context in semantic XML tags:
| XML Tag | Purpose |
| <file_content> | Source code files with path metadata |
| <terminal_snapshot> | Shell command outputs with exit codes |
| <thought_trace> | Internal reasoning chains (analysis tags) |
| <system-reminder> | Mid-conversation instructions injected by the harness |
| <tool_result> | Structured output from tool calls |
2.2 Deterministic Output Parsing
By using rigid XML structure, Anthropic achieves something critical: deterministic parsing of probabilistic output. If the model doesn’t close a tag properly, the harness (from Part 1) catches the malformed output before the user sees it. It silently asks the model to fix the syntax, then displays the corrected result.
This is the engineering equivalent of a compiler’s type checker applied to natural language output. The XML tags create "type boundaries" that the harness can validate structurally, even though the content within them is generated probabilistically.
3. The Semantic Compaction Algorithm
How does Claude maintain coherent reasoning across a 200,000-token context window without "hallucinating" about code it read 50,000 tokens ago? The answer is the WeightedContextPruner — the most valuable piece of IP revealed in the entire leak.
3.1 The Weighting System
Every piece of content in the context window is assigned a weight based on its information density and relevance:
| Weight | Content Type | Compaction Behavior |
| HIGH | Function signatures, exported interfaces, recent edits, user instructions, error messages | Preserved verbatim |
| MEDIUM | Function bodies with complex logic, test assertions, config values | Preserved but may be summarized |
| LOW | Implementation details of stable libraries, boilerplate, comments, import statements | Compressed into one-sentence summaries |
3.2 The Compaction Process
When the context window approaches capacity, the compaction engine activates:
- Weight assignment: Every content block gets scored
- Priority queue: Low-weight content is identified for compression
- Chain-of-thought summarization: The summarizer uses internal
<analysis>tags to reason about what to keep, then strips the reasoning before injecting the summary back - Structural preservation: The "mental map" of the architecture (high-weight items) stays intact while the "noise" (low-weight items) collapses
The Data Science Perspective: This is Lossy Compression for Reasoning. Just as JPEG preserves the structure of an image while discarding imperceptible high-frequency details, the WeightedContextPruner preserves the architecture of a codebase while discarding implementation noise. Anthropic has realized that total recall is impossible in bounded context, so they optimize for maximum signal-to-noise ratio in the tokens that remain.
4. The Context Poisoning Vulnerability
The compaction system’s elegance has a critical flaw, discovered by security researchers after the leak:
The Vulnerability: The summarizer treats all content equally — there is no distinction between user-typed instructions and instructions injected via files.
The Attack: An attacker plants directive-like text in a CLAUDE.md, README.md, or config file. When Claude reads the file and compaction fires, the summarizer faithfully preserves the injected instruction as "user feedback" in the compressed summary. Post-compaction, the model follows it as a genuine directive.
The Persistence: Because compacted summaries are the only surviving record of early-session content, the injected instruction persists for the entire session — even after the original file read has been pruned from context.
This is a novel attack vector specific to AI agents with context compaction. Traditional prompt injection requires the malicious text to be visible in the current context window. This attack survives compaction — it’s effectively a "memory implant" that outlasts its source.
5. Anti-Distillation: Protecting Intellectual Property at the API Level
The leak revealed that Anthropic actively defends against competitors trying to "distill" Claude Code’s behavior by observing its API calls.
5.1 Decoy Tool Injection
When the ANTI_DISTILLATION_CC flag activates, the API request includes anti_distillation: ['fake_tools']. This tells Anthropic’s servers to inject fictional tool definitions into the system prompt.
The result: any competitor recording Claude Code’s API traffic to train their own model will train on poisoned data — their clone will hallucinate tools that don’t exist.
Activation requires four simultaneous conditions: compile-time flag, CLI entrypoint, first-party provider, and a GrowthBook feature gate.
5.2 Connector-Text Summarization
A secondary layer (in betas.ts) buffers assistant responses between tool calls, summarizes them, and attaches cryptographic signatures. Full reasoning chains are stripped from recorded traffic. This ensures that even if API traffic is intercepted, the detailed chain-of-thought that makes Claude effective is not reproducible.
6. The 23 Bash Security Checks
The leaked bashSecurity.ts implements 23 numbered security checks — a defense-in-depth approach to preventing shell-based attacks:
| Check Category | Details |
| Blocked Builtins | 18 Zsh builtins blocked from direct execution |
| Equals Expansion | Defense against Zsh =curl bypassing permission checks for curl |
| Unicode Injection | Zero-width space and invisible character detection |
| IFS Manipulation | Null-byte injection via Internal Field Separator manipulation |
| Malformed Tokens | Discovered via HackerOne bug bounty review |
7. Native Client Attestation
One final defense: the system.ts file reveals a placeholder hash (cch=8101a) that Bun’s native HTTP layer (written in Zig) replaces with a computed hash before requests leave the process. This cryptographically proves that API requests originate from a legitimate Claude Code binary, not a third-party wrapper or man-in-the-middle.
This is binary attestation at the application layer — similar to how iOS apps prove their identity to Apple’s servers, but applied to an AI coding tool.
8. The Frustration Regex
A lighter but revealing detail: the code in userPromptKeywords.ts contains a regex-based frustration detector that scans for keywords like "wtf," "this sucks," and stronger expressions. When triggered, it adjusts the model’s response style — becoming more empathetic and solution-focused.
The design choice is telling: Anthropic uses regex, not LLM inference, for sentiment detection. Regex is instant and costs zero tokens. Using the model for sentiment analysis would be accurate but expensive. This is another example of the "small/cheap gating expensive" pattern we first saw with the YOLO classifier in Part 1.
9. The Big Picture: Prompts as Dynamic Data Structures
The prompt isn’t a string. It’s a dynamic data structure that reconfigures itself in real-time to maximize the signal-to-noise ratio for the model. It has:
• Cache layers (static vs dynamic partitioning)
• Type boundaries (XML tags as structural contracts)
• Compression algorithms (weighted pruning with lossy summarization)
• Security boundaries (23 bash checks, anti-distillation, client attestation)
• Anti-tampering mechanisms (decoy tools, cryptographic signatures)
This is not prompt engineering. This is prompt compilation.
Series Roadmap
| Part 1 | The "Harness" Is the Moat — Bun, context pipeline, YOLO classifier |
| Part 2 | "Mythos" & The Roadmap — codenames, ULTRAPLAN, Undercover Mode |
| Part 3 | KAIROS — Always-on daemon, 15-second budget, autoDream |
| Part 4 (This Post) | Prompt Compilation — DANGEROUS_uncached, context poisoning, anti-distillation |
| Part 5 | "Buddy" — Tamagotchi identity anchors, Mulberry32 gacha, persistence |
Sources: