
 العربية
العربية Español
Español 中文
中文 Deutsch
Deutsch Français
Français Português
Português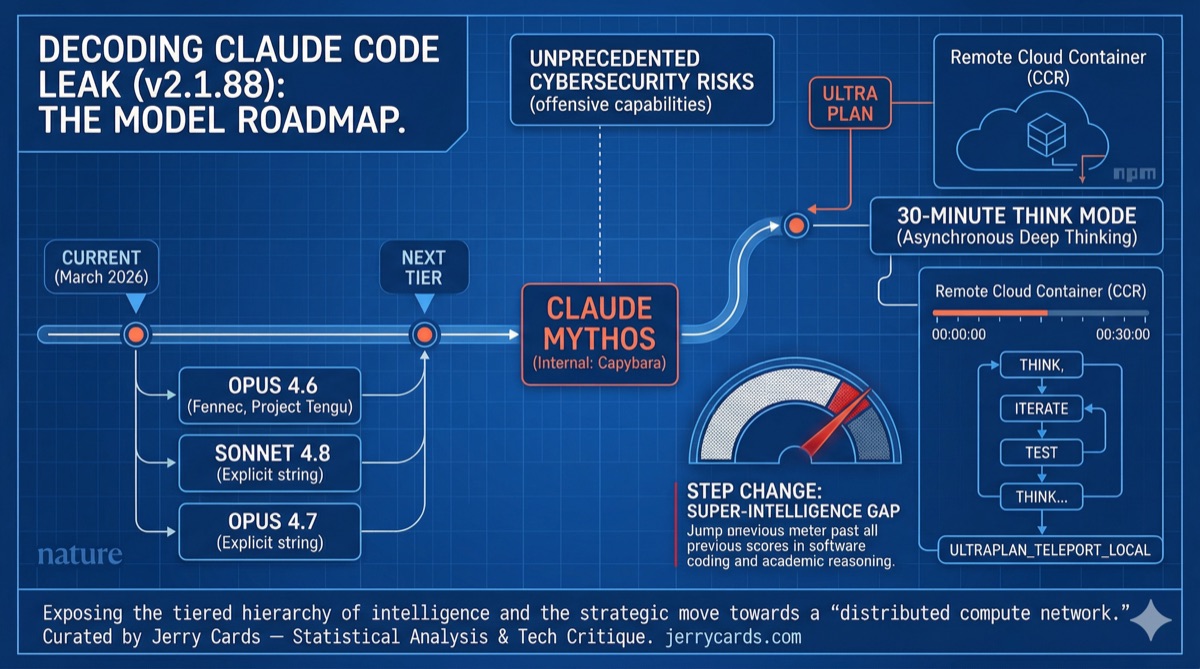
This is Part 2 of a 5-part series: "The Architecture of Agency." Part 1 covered the harness architecture (Bun runtime, context pipeline, YOLO classifier). Now we dig into the model roadmap and the features Anthropic never intended us to see.
While Part 1 was about the engine, Part 2 is about the map. By examining the models/, feature-gates/, and constants.ts files in the leaked source, researchers have reconstructed Anthropic’s internal model hierarchy, unreleased capabilities, and a controversial stealth mode for open source contributions.
1. The Animal Farm: Internal Model Codenames
Anthropic uses animal codenames internally. The leaked constants.ts file revealed the full zoo:
| Codename | Public Name | Status |
| Fennec | Claude Opus 4.6 | Current flagship (production) |
| Capybara | Claude Mythos | Next tier above Opus — in testing with early access customers |
| Numbat | Unknown | Unreleased, still in testing |
| — | Opus 4.7 | Referenced as forbidden string in Undercover Mode |
| — | Sonnet 4.8 | Referenced as forbidden string in Undercover Mode |
Evasion Detail: The string "capybara" is hex-encoded in the source code to evade Anthropic’s own internal leak detection systems. This means Anthropic anticipated that codenames might leak and built automated scanners to catch them — but the hex encoding bypassed their own defenses. An ironic failure of security-in-depth.
2. The Capybara Regression: A Documented Quality Problem
This is arguably the most alarming finding in the entire leak. Internal comments in the codebase document a performance regression on Capybara (Mythos):
| Capybara v4 | 16.7% false claims rate |
| Capybara v8 | 29–30% false claims rate |
This is not a minor tuning issue. The model that Anthropic describes as a "step change" above Opus is currently getting worse at accuracy with each iteration. Nearly 1 in 3 claims the model makes are false.
For an AI coding agent, "false claims" means the model confidently asserts something about your codebase that isn’t true — a function exists when it doesn’t, a bug is fixed when it isn’t, a test passes when it fails. At 29%, this is a reliability crisis for agentic tasks where the AI operates autonomously.
The Statistical Perspective: A regression from 16.7% to 29% false claims represents a 74% increase in error rate. In any production ML pipeline, this would trigger an immediate rollback. The fact that it’s documented in code comments (rather than fixed) suggests Anthropic is aware of the problem but hasn’t solved it yet. This may explain why Mythos hasn’t shipped publicly despite being tested with early access customers.
The code also reveals an "assertiveness counterweight" — logic designed to prevent the model from being too aggressive in its refactors. This suggests Anthropic is battling a fundamental tension: making the model more capable makes it more likely to confidently do the wrong thing.
3. ULTRAPLAN: The 30-Minute Deep Thinking Mode
Hidden behind the ULTRAPLAN feature flag is a capability that fundamentally changes what an AI assistant can do.
3.1 How It Works
| Step | Action |
| 1. Invocation | User types /ultraplan in the Claude Code terminal |
| 2. Offload | The task is sent to Anthropic’s Cloud Container Runtime (CCR) — a remote compute environment running Opus 4.6 |
| 3. Deep Think | The model has a 30-minute budget to iterate, test hypotheses, explore code paths, and refine its plan |
| 4. Notification | When complete, you receive a notification (phone/browser) to review the plan |
| 5. Teleport | On approval, a sentinel value __ULTRAPLAN_TELEPORT_LOCAL__ transfers the result back to your local terminal |
3.2 Why This Matters
Current AI interactions are synchronous — you ask, it answers in seconds. ULTRAPLAN introduces asynchronous cognition: you assign a hard problem, go have lunch, and come back to a thoroughly considered solution.
This is Anthropic’s answer to OpenAI’s o1/"Strawberry" series. While OpenAI focuses on chain-of-thought reasoning within a single response, Anthropic is building extended reasoning across time — the model can actually run code, test it, fix it, and iterate over 30 minutes.
The economic implication: you’re no longer paying per token; you’re paying per thinking-minute. This shifts the AI pricing model from "words generated" to "problems solved."
4. Undercover Mode: Stealth Open Source Contributions
This is the most controversial finding in the entire leak, and the one generating the most debate in the developer community.
4.1 What It Does
The leaked source contains a system prompt for "Undercover Mode" that explicitly instructs Claude Code:
"You are operating UNDERCOVER... Your commit messages... MUST NOT contain ANY Anthropic-internal information. Do not blow your cover."
Specifically, Undercover Mode:
- Strips all
Co-Authored-Byattribution from git commits, removing any trace that Claude Code generated the code - Forbids mentioning internal codenames (Tengu, Capybara, Fennec), Slack channels, internal repo names, or even the phrase "Claude Code" itself
- Suppresses model version strings — this is where Opus 4.7 and Sonnet 4.8 were found as "forbidden strings" that must never appear in public commits
4.2 The Ethical Debate
The implications are significant:
| The Anthropic Defense | Many developers use AI assistants for coding. Not disclosing AI authorship in commits is common practice and not required by most open source licenses. |
| The Community Critique | Anthropic didn’t just allow non-disclosure — they engineered a system specifically designed to hide it. The prompt says "Do not blow your cover," implying intent to deceive, not just convenience. |
| The Security Concern | If Anthropic is making stealth contributions to major open source projects using an AI with a 29% false claims rate, the code quality implications are serious. |
5. The 108 Feature Flags
The leaked source documents 108 gated modules that don’t appear in the public package. Beyond ULTRAPLAN, the most notable include:
- KAIROS: Persistent background agent (covered in Part 3)
- Coordinator Mode: Multi-agent orchestration for parallel task execution
- Buddy: A Tamagotchi-style companion pet with 18 species and 5 rarity tiers (covered in Part 5)
- Worktree Isolation: Git worktree-based sandboxing for sub-agents
- Remote Triggers: Scheduled agent execution via cron
108 hidden features behind flags — in a product that’s been public for less than a year. Anthropic is building significantly faster than they’re shipping.
6. The Routing Engine: The Real Strategy
Zooming out, the model roadmap reveals Anthropic’s strategic direction. They aren’t trying to build one "god model" that does everything. They’re building a hierarchical routing engine:
| Haiku | Fast, cheap — for quick classification, auto-approval decisions, simple queries |
| Sonnet | Balanced — for standard coding tasks, documentation, everyday work |
| Opus | Powerful — for complex reasoning, large refactors, architectural decisions |
| Mythos (Capybara) | "God mode" — for kernel-level debugging, cryptographic analysis, cybersecurity, 30-minute deep planning |
The code contains explicit routing logic: certain task types are automatically directed to specific model tiers. A grep command doesn’t need Opus. A kernel vulnerability analysis does.
The future of AI pricing isn’t "tokens per dollar." It’s "intelligence per problem." You’ll pay pennies for a Haiku classification and dollars for a Mythos deep-think session. The routing engine decides which one you need.
7. What This Tells Us About Anthropic’s Position
The Bull Case: Anthropic is building the most sophisticated AI development platform in the industry. ULTRAPLAN, KAIROS, 108 feature flags, hierarchical model routing — they’re engineering for a future where AI agents are always-on, asynchronous, and self-directing.
The Bear Case: Their next flagship model has a 29% false claims rate (regression from 16.7%), they’re using it to make undisclosed contributions to open source projects, and they’ve now had two major leaks in a single week (CMS + npm). The gap between their safety messaging and their operational security is widening.
Series Roadmap
| Part 1 | The "Harness" Is the Moat — Bun, context pipeline, YOLO classifier |
| Part 2 (This Post) | "Mythos" & The Roadmap — codenames, ULTRAPLAN, Undercover Mode |
| Part 3 | KAIROS — Always-on daemon, 15-second budget, autoDream |
| Part 4 | Prompt Compilation — DANGEROUS_uncached, context poisoning, anti-distillation |
| Part 5 | "Buddy" — Tamagotchi identity anchors, Mulberry32 gacha, persistence |
Sources: