
 العربية
العربية Español
Español 中文
中文 Deutsch
Deutsch Français
Français Português
Português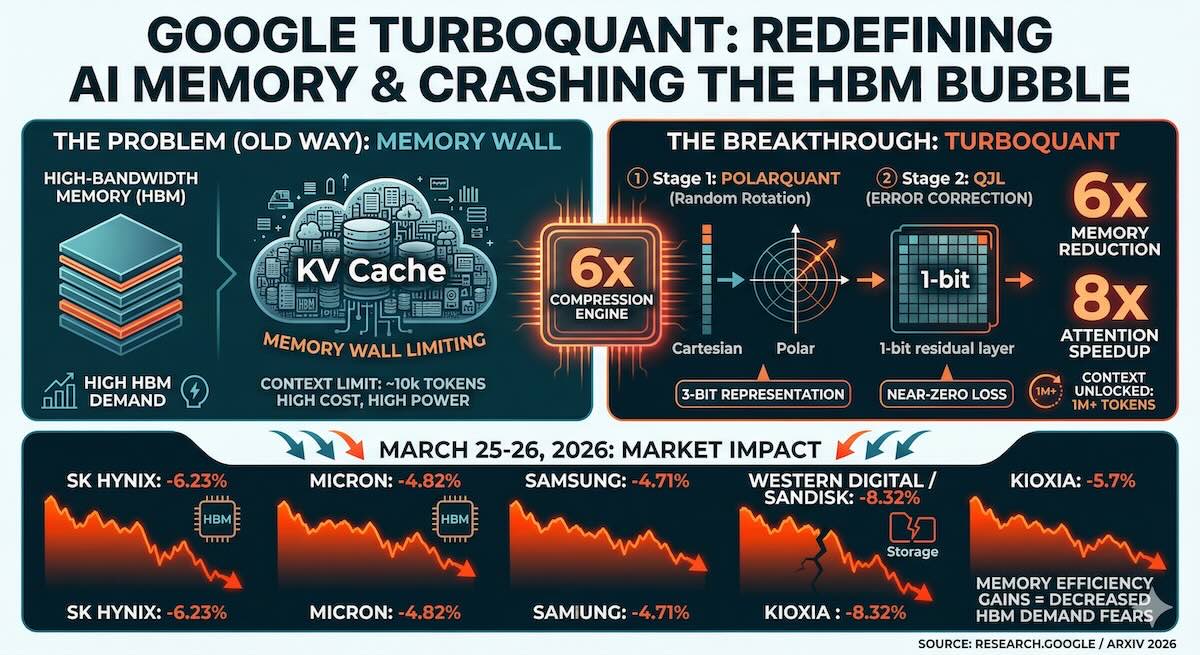
On March 24, 2026, Google Research unveiled TurboQuant, a set of algorithms that effectively solves one of AI's most expensive bottlenecks: the KV (Key-Value) Cache. The market reaction was immediate and violent, wiping out billions in market cap for the world's leading memory producers.
The Core Problem: The "Memory Wall"
As Large Language Models handle longer contexts (thousands of pages of text), they must store a "Key-Value Cache" — essentially the AI's short-term working memory. This cache grows linearly with context length. Until now, this meant you either needed massive amounts of High-Bandwidth Memory (HBM) or you faced a "memory wall" where the AI simply ran out of room.
The Breakthrough: The TurboQuant Suite
TurboQuant (set for ICLR 2026) isn't just one algorithm — it's a two-stage mathematical shield that reaches the theoretical limits of compression.
- PolarQuant (Stage 1): Instead of using standard Cartesian coordinates (X, Y, Z), it applies a random rotation to the data and maps it onto Polar Coordinates (radius and angle). This makes the data distribution highly predictable, allowing compression into a tiny 3-bit representation without needing normalization constants — metadata that usually eats up all compression gains.
- QJL — Quantized Johnson-Lindenstrauss (Stage 2): Even at 3-bit, some error remains. TurboQuant uses a 1-bit residual layer to correct this error. This "error checker" ensures attention scores stay accurate, achieving near-zero loss in performance.
The Performance Metrics
| Memory Reduction | 6x — shrinks the KV cache memory footprint by 84% |
| Speed Improvement | 8x — eight-fold increase in throughput for attention operations on NVIDIA H100 GPUs |
| Vector Search Indexing | 0.001 seconds — down from hundreds of seconds, enabling real-time semantic search at any scale |
The Economic Fallout: The Memory Sell-Off of March 2026
The announcement sent shockwaves through the semiconductor sector on March 25-26, 2026. Investors feared that if AI models require 6x less memory, the high-margin demand for HBM would evaporate.
| Micron (MU) | -4.82% | Fears of reduced HBM demand hit investor sentiment |
| Samsung Electronics | -4.71% | Dragged down the entire KOSPI index |
| SK Hynix | -6.23% | Second-largest memory producer took the biggest hit |
| Western Digital / SanDisk | -8.32% | Storage giants hit hardest in the sell-off |
| Kioxia (Japan) | -5.7% | Japanese memory producer followed the global trend |
The Counter-Argument: Jevons Paradox
Wall Street analysts from Morgan Stanley and JPMorgan have already labeled this sell-off as a "knee-jerk reaction." They argue that Jevons Paradox will apply: as the cost of "memory per token" drops, developers won't buy less memory — they will build 6x larger context windows or deploy AI to 6x more devices, eventually increasing total hardware demand.
History supports this view. When GPU compute got cheaper through better software, we didn't use fewer GPUs — we trained bigger models. The same logic applies here: cheaper memory means bigger context windows, more AI agents, and more devices running inference.
The Bottom Line
TurboQuant is a genuine breakthrough that reaches the theoretical limits of KV cache compression. But rather than killing the memory industry, it is more likely to supercharge adoption — unlocking million-token context windows on everyday hardware and bringing AI to billions of devices that couldn't run it before.
The real losers aren't memory companies. They're cloud providers who charge per-token for inference. When everyone can run massive context locally, the "AI Tax" starts to disappear.
Sources: Google Research Blog, arXiv: TurboQuant Paper, arXiv: QJL Paper