
 العربية
العربية Español
Español 中文
中文 Deutsch
Deutsch Français
Français Português
Português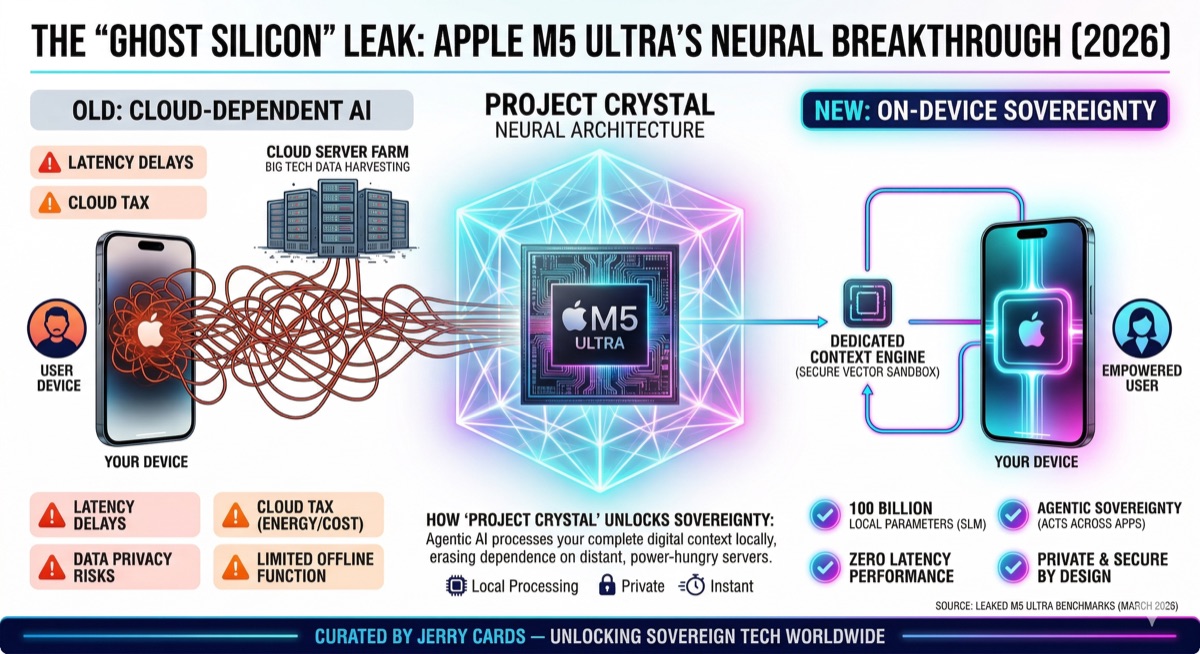
For the last three years, we have been told that "real" AI requires massive server farms, billion-dollar data centers, and endless cloud subscriptions. Apple's M5 chip architecture just proved everyone wrong.
The Architecture Breakthrough: Neural Accelerators in Every Core
The biggest leap in the M5 generation is what Apple calls Fusion Architecture. While the 16-core Neural Engine (NPU) still handles background AI tasks, Apple has embedded Neural Accelerators (NAs) into every single GPU core.
- M5 Max with 40-core GPU = 40 additional AI processing units working in parallel with the Neural Engine
- 4x leap in AI compute throughput compared to M4
- Specifically optimized for Transformer architectures (the foundation of all modern LLMs)
- Time-to-first-token dropped by 300% compared to M4
70B Parameters on a Laptop: The Numbers
For years, the holy grail of local AI was running a 70B parameter model with usable speed on a portable device. The M5 Max has crossed that threshold:
- 614 GB/s unified memory bandwidth — faster than many dedicated server GPUs from 2024
- Llama-3-70B at ~110-130 tokens/second on M5 Max (128GB) — faster than most cloud APIs
- 30B MoE model: under 3 seconds to first token
- 14B dense model: under 10 seconds to first token
- 60-90W power draw vs 600-800W for an equivalent NVIDIA RTX 5090 rig
- 20 hours of AI agent runtime on a single battery charge
The Sovereign AI Perspective
For those who value running their own Bitcoin nodes or hosting private servers, the M5 era represents the decentralization of intelligence.
The "Cloud Tax" is not just the monthly subscription to OpenAI or Anthropic. It is three taxes rolled into one:
- The Privacy Tax: Your data, prompts, and business logic travel through someone else's servers
- The Latency Tax: Every query requires a round-trip to a distant data center
- The Dependency Tax: Your business stops functioning if the API goes down or prices change
By moving the brain of your business onto M5-class local hardware, you eliminate all three. You are no longer renting intelligence — you own the means of production for your own insights.
The Product Sweet Spots for 2026
| M5 Pro (64GB) | The Value Play. 307 GB/s bandwidth. Runs 30B models and quantized 70B models comfortably. Best performance-per-dollar for most developers and entrepreneurs. |
| M5 Max (128GB) | The Power Play. 614 GB/s bandwidth. Full 70B models at 110+ tokens/sec. For serious AI development and production workloads. |
| M5 Ultra (Mac Studio) | The Server Killer. Expected 512GB-1TB unified memory. Will enable running expert-level MoE models previously restricted to $100k+ server clusters. One desktop replaces a rack. |
Project Crystal: The Secure Vector Sandbox
Leaked details suggest Apple is developing a framework called "Project Crystal" that introduces a Secure Vector Sandbox directly into the silicon's memory controller:
- Zero-knowledge context: Your entire digital footprint — emails, code repos, financial data — indexed into a hardware-locked local vector database
- Agentic sovereignty: AI acts as a true agent across your apps without a single packet of data leaving your device
- Not just answering questions — cross-referencing calendars, drafting contracts from local templates, preparing pull requests, all locally
The Bottom Line
The transition from M4 to M5 is not just a spec bump. It is a fundamental re-engineering of how silicon handles intelligence. For the first time, a laptop can match or exceed cloud AI performance while keeping everything private, offline, and under your control.
The Cloud Tax era is ending. The Sovereign AI era has begun.
Sources: Apple Newsroom, Apple ML Research, AppleInsider, Creative Strategies